發現了程序的問題再回頭去調試,在查找程序錯誤時就不可避免地要花大量時間。要調高開發效率,最好是在編寫代碼時就避免一些常見的低級錯誤,這樣可以節約大量的調試時間。
有些編程錯誤差不多是每個 LabVIEW 程序員都曾遇到過的。在編寫相關代碼的時候,對這些問題多留心一下,就可以大大減少調試時間。
1. 數值溢出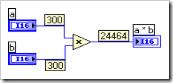
圖1:數值溢出錯誤
圖1 中的 VI 只做了一個簡單乘法 300*300 ,不加思索就應該知道答案是 90000,但程序中乘法節點給出的結果卻是 24464。乘法節點是不會錯的,錯誤是由於程序中使用的數據類型是 I16。I16 能表示的最大數目只有32767,所以在乘法計算中出現了溢出。
避免此類錯誤的方法是,在程序中使用短數據類型時,一定要確認程序中的數據絕不會超出該類型可以表示的範圍。
2. For 循環的隧道
數據傳入傳出循環結構可以通過移位寄存器(Shift Register)和隧道(Tunnel)兩種方式。隧道又有兩種類型:帶索引的和不帶索引的。
移位寄存器一般用在需要局部變數的情況下,循環運行一次的輸出數據要作為下次運行的輸入數據使用;循環外的數組數據通過帶索引的隧道在循環體內就可以直接得到數組元素;除此之外,簡單地在循環內外傳遞數據,使用一般的隧道就可以了。
值得一提的是,如果一個數據傳入循環體,又傳出來,那麼就應該使用移位寄存器或帶索引的隧道來傳遞這個數據,盡量不要使用不帶索引的隧道。因為 For 循環在運行時,循環次數有可能為0。在循環次數為0時,大多數情況,用戶還是希望傳出循環的數據就是傳入值,但使用不帶索引隧道時,輸入值有時會被丟失的。如果使用移位寄存器,即使循環次數為0,也不會丟失傳入的數據。因為移位寄存器在循環上的兩個接線柱指向的實際是同一塊內存(參考:LabVIEW 程序的內存優化),而輸入輸出兩個隧道指向的是不同的內存,數據不一定相同。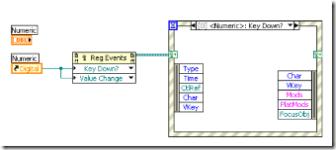
圖2:For 循環上的隧道
圖2中的程序, vi reference 傳入,再傳出循環均使用了隧道。如果循環次數為0(Controls數組為空),vi reference 再傳出循環時,信息就丟失了。這不但有可能造成後續程序的錯誤,而且由於 vi reference 的信息丟失,再無法關閉打開的 vi,造成了程序泄漏。
Error 數據線(黃綠色的粗線)在傳入傳出數組時,一定要使用移位寄存器。原因還不僅是為了防止在循環次數為0時,錯誤信息丟失。通常一個節點的 Error Out 有錯誤輸出,意味著後續的程序都不應該執行。在錯誤的情況下繼續執行程序代碼,風險非常大,可能會引起程序,甚至系統崩潰。只有使用移位寄存器,某次循環產生的錯誤才會被傳遞到後續的循環中,從而及時阻止後續循環中的代碼被運行。
3. 循環次數
與其它語言相比,LabVIEW 的 For 循環有一大特點,在某些情況下它並不要求一定要輸入循環次數,而可以根據輸入數組的大小自動決定循環次數。通過帶索引的隧道,可以把數組分解成元素傳遞到循環體內,此時不需另行設置循環次數N,循環的次數就是數組的長度。每次循環,帶索引的隧道便給出一個元素。
循環體上可以有兩個或更多的輸入數組使用帶索引的隧道,此種情況下容易引起錯誤。這時,循環的次數等於幾個數組中長度最短的那個數組的長度。如果另外又設置了循環次數N,那麼循環次數就是N與輸入數組長度這兩者的最小值。調試時,如果發現一個本該運行多次的循環沒有運行,那麼很可能就是因為它的一個輸入數組是空的。
While 循環同樣也可以使用帶索引的隧道,但是我不建議大家這麼用——如果需要用到帶索引的隧道,還是使用 For 循環更為適宜。因為 while 循環的循環次數不由數組個數決定,而是由停止條件決定的。如使用了帶索引的隧道,你還需要考慮當數組大於、小於循環次數時,程序應該如何處理,所以還是在循環體內作索引比較方便。如果希望循環次數與數組大小保持一致,那自然是用 For 循環的程序更加清晰易懂了。
4. 移位寄存器的初始化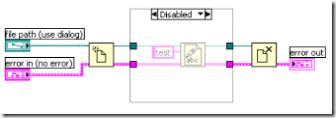
圖3:沒有初始化的移位寄存器
看圖3中這個程序,因為它在 while 循環上使用了帶索引的隧道,所以可讀性不那麼好。array out 的運行結果是什麼,還要考慮一陣子才能給出答案。實際上這個程序,即使輸入不變,每運行一次,array out 的結果都是不一樣的,它的長度一直在增加。這個問題就出在沒有給程序中的移位寄存器一個初始值。
沒有初始化的移位寄存器,總是保存上次運行結束時的數據。這個特點在某些情況下可以被程序員利用,比如用它當作全局變數,隨時把數據存入或取出(一個例子是《如何使用 VI 的重入屬性》中的圖4)。但多數情況下移位寄存器還是被用作為循環內部的局部變數的,這時就一定要對它初始化,以防止潛在的錯誤。
5. Cluster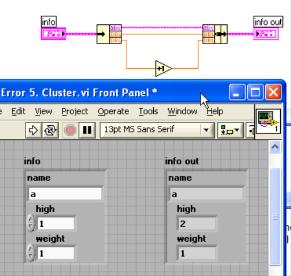
圖4:Cluster 傳遞數據出錯
圖4的程序中有個奇怪的錯誤,明明應該是 weight 加 1 怎麼運行完后的結果變成了high 加 1 了呢?直接揭開謎底吧,原因是 Cluster 中的元素有個順序,這個順序可以和界面上看到的順序不一致。分別滑鼠右擊程序中的兩個 Cluster,選擇“Reorder Controls in Cluster”,就可以看到每個元素在 cluster 中的編號。info out 中的 high 實際上編號是 2,第三個元素。
為了避免 cluster 中用可能出現的錯誤,以及讓 cluster 應用起來更方便,使用 cluster 最好遵循以下原則:
6. 并行運行
LabVIEW 是自動多線程的編程語言,這一點在方便用戶的同時,也會帶來一些麻煩。比如最常見的情況,多線程會引起數據或資源的競爭錯誤(race condition)。
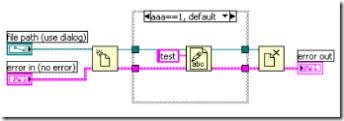
圖5:兩個并行運行的子 VI
圖5是一個簡單的兩個子 VI 并行運行的例子,在這個例子中就隱藏著一個潛在的問題。并行執行的兩部分程序,先後次序是不定的。有可能關閉程序中的引用數據(綠色的線上的數據)的節點在子 VI B 結束前運行。而子 VI B 是要用到這個參考數據的,這是子 VI B 就會因為它所需要的數據失效而產生錯誤。
[admin via 研發互助社區 ] LabVIEW 編程常見錯誤已經有5126次圍觀
http://cocdig.com/docs/show-post-44843.html
